ABOUT
Under Construction
Origin story
Verbatim, Baby! was born from need - sure, a personal, niche, obscure need, but need nonetheless. This page provides a personally delivered account of what seemed like a simple need, but then evolved out of control.
This section is written by me as myself, Yolanda Brown, a former professional tattoo artist and verbatim legal transcriber, just in plain, non-technical language. It should be noted that I’m uncertain of what to add to that, and that uncertainty stems from not being quite sure what I’ve become during the Verbatim, Baby! Project.
In the very beginning, at the end of 2024, I thought it would be fun to learn Python and maybe create a little Pong game or something. The plan was not to do anything more than a little bit of hobby-coding. Unfortunately, most plans don’t work out as intended, and this was one of those.
Around the beginning of 2025, I was sampling online ASR generation, but samples were limited in size, and it was hard to pick one service out of hundreds. Additionally, even with ASR generation, you still encountered editing issues. Ideally, you’d need a transcript editor that could hold both audio and transcript in a synchronized editing window that saves edits as you go. Only, I couldn’t find anything even close.
Like any normal person, I vented to AI and asked for suggestions, and the AI in question at this time was ChatGPT. It was really helpful, and I looked at a lot of resources, but still couldn’t find what I was looking for. Something that came close-ish was WizWisp, which can be downloaded onto the hard drive from the Microsoft Store, but I needed an editor, not just the ASR. So ChatGPT said, Well, build it. You’re learning Python. I can help you. It’ll be fun, I promise.
I was a little stunned. At that stage, I’d only learned the little "Hello, World!" box and a very simple form. I mulled this over for a few days, and around that time, people were reporting 'vibe-coding' with AI, and those first reports really sealed the deal.
The Very Beginning
At the very beginning, I showcased my spectacular skills by creating a window and "Load audio" and "Play" buttons that were placeholders. I was very proud, but from that point on, AI had to be the lead coder, and honestly, ChatGPT was a superstar. It created a roadmap to Whisper with a relatively short timeline. Not only did it create all the code, but it also provided a detailed explanation of how everything worked and interacted with other parts of the code, before explaining where and how to paste it into the code file.
I was very excited once we had that expandable window that could load, play, and skip audio clips forward and back, and I was ready for the next step. During the planning of the roadmap, we discussed open-source ASR engines that I could run offline and decided on Whisper. I was arrogant, and I insisted that the Whisper model we started with be downloaded and accessed from my hard drive. I still feel the same way, especially concerning client-confidential audio.
The process of getting Whisper and getting it to run involved many Python downloads – have a peek at a section of the final imports list:
After the initial joy of playing and manipulating audio, debugging Whisper in an interface was a definite downer. It was a constant stream of me copying and pasting the error, and ChatGPT giving me a new list of command lines for more Python packages, me placing code in the wrong place, or me not paying attention to indents. It was mostly me – I was the problem, but at least I was self-aware enough to understand that I was learning new things at a really rapid rate, so it was forgivable internally.
When the "Transcribe" button finally stopped producing red errors, my heart nearly stopped. The 30-second test audio that I recorded in my own voice days earlier was finally inside the editing window. There were no timestamps or a speaker designation, but my test words were there, and that's all that mattered. Still basking in that glory, I quickly recorded an Afrikaans test audio, as that's my second native language. I loaded the audio and hit "Transcribe," but what followed can only be described as confusion.
I looked at the output, but didn't recognize the language. I played the audio, thinking there must be something wrong with it, but no. It was my test recording, and it was fine. I said to ChatGPT I think Whisper did the wrong language. Can we force it to recognize this as Afrikaans? Of course, we could. We weren't just pioneers in coding. We were reality breakers, according to ChatGPT. Architects. Nothing could ever hold us back.
So we just casually set about defining all of the Whisper languages in the code and attaching them to a language selector. While we were at it, we also set up timestamps and speaker segmentation, and again, because of my human learning mistakes, it was a few days before everything was ready for another test. During that test, we gained rudimentary timestamping and segmentation that designated every line [SPEAKER X], and again, the Afrikaans output was garbled. I became paranoid, scrolling back through our entire process because I was convinced that I messed up code somewhere and broke Whisper.
For any accidental reader who may be familiar with Afrikaans, but unfamiliar with Whisper and its Afrikaans abilities, brace yourself. This sentence is from a more recent Afrikaans recording volunteered by a teacher with good pronunciation:
"Dit kan natuurlijk goed of slecht wees, maar omdat ek so mindel van weet, en ek sal nie sê, dit is raar genoem, my lijn van werk nie."
What she really said, verbatim, was:
Dit kan natuurlik goed of sleg wees, maar omdat ek so min daarvan weet, en -- ek sal nie sê dis rêrig in my lyn van werk nie."
If you know Afrikaans, you can see why I thought I broke Whisper. I said to ChatGPT that it looked like Dutch spelling, but at the time, I didn't know Dutch well enough to be able to tell. That's when I had my first meeting with the phrase, "digital colonization." There was a long explanation about how Afrikaans came from Dutch, and Whisper has a larger internal dictionary and training for Dutch, so that's the fallback for Afrikaans. It doesn't really know Afrikaans – it just claims to because it may as well be Dutch. My Afrikaans half was so offended that I nearly quit my own project.
Facing Down Dutchikaans
Once I overcame the offense, I decided to investigate the issue. I spoke to Afrikaans transcribers, and all of them scoffed at Afrikaans ASR, calling it garbage and a waste of time. I mean, I can see why, but surely there had to be a way around it. There was: Substitution files. First, we created a placeholder selector on the toolbar, and then it took a few days to get the system to recognize and use the selected file, but when it did, it was really sweet.
Finally seeing this in the debug and a much more accurate transcript made the struggle worthwhile:
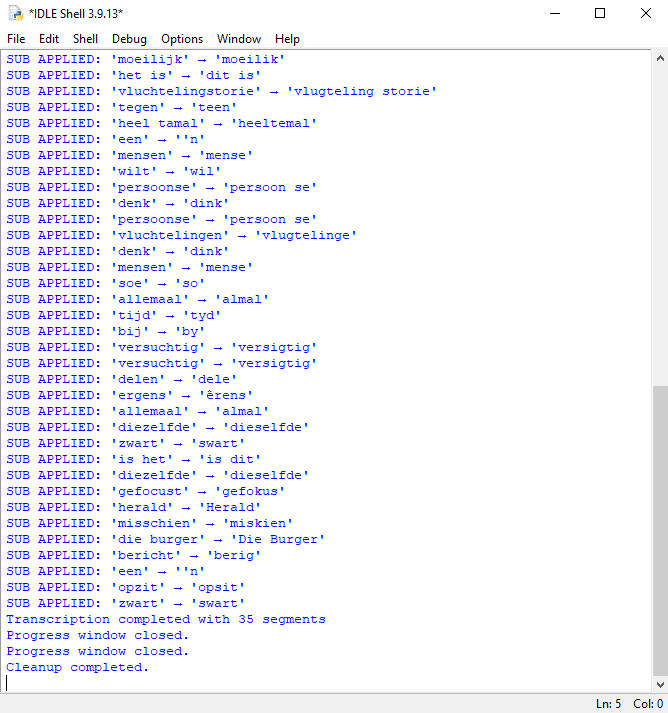
Now that we had working substitutions, I needed more speech to flesh out the master file. For this, I gathered up a group of Afrikaans speakers and explained my project. They were bored to death, but understood why I needed speech, and they were happy to become donors. I didn't want scripted speech because in a transcription environment, speakers don't follow scripts. I encouraged my speakers to pick any topics, and they went to town. Two opted for a conversation-style recording with me because they had things to get off their chests.
Both are women – one spoke candidly about addiction and navigating recovery. The other spoke about a failed marriage and divorcing the father of her children, her subsequent marriage to a woman who turned violent, leading to her losing custody of her children, the ensuing divorce, and her own recovery. They did this over a cup of coffee, and both treated it as a therapy session of sorts. When I checked in with them a day later, both reported the experience to be cathartic – a cleansing of the soul because they got to speak about their greatest failures, saying things they never told anyone. When I asked if they wished to retract their written approval for me to use their audio, both declined and offered more.
The other speakers are a variety: A woman in the male-dominated field of car parts; Two teachers, one male, one female; A native English neurodivergent trying to learn Afrikaans through painful conversations with Google Gemini (spoiler – he gave up because he became convinced that Gemini was harming his learning); A male car parts salesman; A female OT student. What they gave me is priceless – spontaneously spoken Afrikaans by the realest of people in its full, code-switching glory. These amazing people donated so much of their speech that I had to pause them. I simply don't have the time to process all of it fast enough.
Together with their unique, spontaneous words, each speaker also gave a unique speaking pattern. One speaker has a sing-song sort of voice and does not really allow herself a pause after a period. Another amuses themselves so much that most sentences end in a laugh. One has a stutter when he slows down to think. Another speeds up and falls into false starts when dealing with emotions. All of them tripped Whisper up in unique ways, so I ended up creating not only a master subs file, but also eight speaker pattern files. Currently, depending on speaker style, my Whisper accuracy shot up to between 60 and 80% in Afrikaans, a far cry from the initial 10 to 15%.
What Came Next
After fleshing out the master file for a while, the time came to add a translation module. Up to now, hardware wasn't really a problem, but when it came to LibreTranslate and Docker, nothing could get my AMD system to allow them to run. Not together in a way that the software could use, anyway. During those two weeks or so of trying to find workarounds for LibreTranslate to come on board, I cried in front of my computer often. A lot. I was feeling more out of my depth than ever before, and I was starting to doubt ChatGPT.
One morning, I decided to discuss the issue in-depth with DeepSeek, and it identified my hardware as the likely cause of the issue and suggested that I upgrade to an Nvidia GPU and double my RAM to 32 GB. My exact words were, "Bro, I'm a transcriber." DeepSeek understood and convinced me to pivot to Google Translate, even though that would mean that the module itself would need online access. I agreed, and DeepSeek created the code. That was probably the easiest part of the whole project because I just added it in and it worked.
But the Afrikaans issue still bothered me, so I started to look at what we needed for real improvement for everyone, and the answer was real speech data. Real speakers speaking real Afrikaans as they do at home, with a human editing the verbatim transcript and reformatting timestamps to match the exact start and end of sentences, and then snipping both the transcript and audio into those exact sentences in side-by-side packages. That sounded like a lot of work to me, so we created code that would do all of the heavy lifting – all you need is a transcriber to edit and perfect the timestamps, click "Export for ML," and fill out the Speaker Management fields for the manifest.
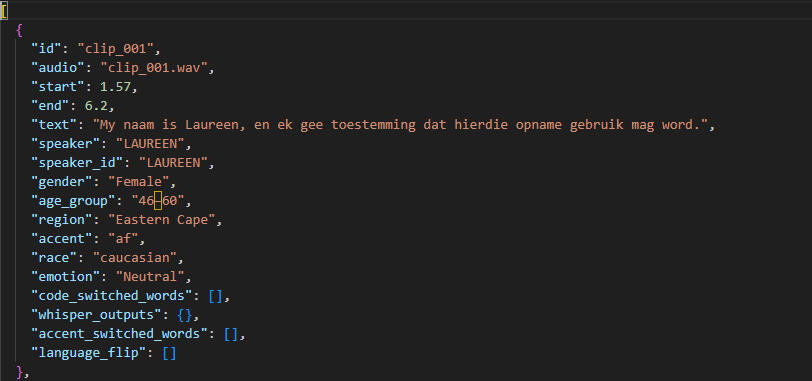
In the context of a speech data package, the manifest serves to identify the speaker, their language, age, accent, code-switching habits, and other vocal quirks. It basically tells the learning machine whose voice it is and the attached demographics.
Current Issues
Any coder reading this already knows the issue - a program of this layered nature has to be modularized. As a monolithic code file, regardless of the fact that it works, it can't be easily prepped for an installer, so that's the next phase of development. I have already started, but this time around, I'm going slower and doing better research before committing. One thing is certain, though: I wouldn't trade my first-ever AI coding experience for anything in the world.
The Future
Nobody knows what the future holds, but we have to agree that AI is here to stay. It’s the kind of thing that can’t be ‘unknowed’ by anyone who used it as a tool and achieved something that would have been entirely impossible otherwise. Undeniably, it’s used for warfare and surveillance, but it’s also used for art and other creative purposes.
There has been a lot of divisive discourse among humans; Artists hate it – they say that AI operates on stolen knowledge and skill. Hollywood ‘panics’ in headlines. But is that not the nature of art? Beauty is in the eye of the beholder, and often, an impressed beholder will mimic. It is said that imitation is the greatest form of flattery. Why not be flattered?
Perhaps we should accept that we cannot drive our stagecoaches everywhere anymore. We need to get off that exposed, wooden seat and into the self-driving car of the future. We are entering an age where everyone can be a collaborator and achieve anything. Do you see an image in your mind’s eye, but you don’t have the skill to realize it? Collaborate with AI. Need software to improve your workflow? Collaborate with AI.
Collaboration does not mean that you sit back and make the AI do all of the work. You, the human, still have to have an idea. Then that idea must be turned into a written prompt with contextual detail – the better your prompt, the better your output. AI does not create anything by itself (yet). It needs humans.